本文共 6795 字,大约阅读时间需要 22 分钟。
项目开发中,如果有定时任务的业务要求,我们会使用linux的crontab来解决,但是它的最小粒度是分钟级别,如果要求粒度是秒级别的,甚至毫秒级别的,crontab就无法满足,值得庆幸的是swoole提供的强大的毫秒定时器。
应用场景举例
我们可能会遇到这样的场景:
-
场景一:每隔30秒获取一次本机内存使用率
-
场景二:2分钟后执行报表发送任务
-
场景三:每天凌晨2点钟定时请求第三方接口,如果接口有数据返回则停止任务,如果接口由于某种原因没有响应或者没有数据返回则5分钟后继续尝试请求该接口,尝试5次后仍然失败则停止该任务
以上的三个场景我们都可以归纳为定时任务的范畴。
Swoole毫秒定时器
Swoole提供了异步毫秒定时器函数:
swoole_timer_tick(int $msec, callable $callback):设置一个间隔时钟定时器,每隔 m s e c 毫 秒 执 行 一 次 msec毫秒执行一次 msec毫秒执行一次callback,类似于javascript中的setInterval()。
swoole_timer_after(int $after_time_ms, mixed $callback_function):在指定的时间$after_time_ms后执行$callback_function,类似于javascript的setTimeout()。
swoole_timer_clear(int $timer_id):删除指定id的定时器,类似于javascript的clearInterval()。
解决方案
对于场景一,经常用在系统检测统计方面,实时性要求比较高,但又能控制好频率,多用于后台服务器性能监控,可以生成可视化图表。可以是30秒获取一次内存使用率,也可以是10秒,而crontab最小粒度只能设置为1分钟。
swoole_timer_tick(30000, function($timer) use ($task_id) { // 启用定时器,每30秒执行一次 $memPercent = $this->getMemoryUsage(); //计算内存使用率 echo date('Y-m-d H:i:s') . '当前内存使用率:'.$memPercent."\n"; }); 对于场景二,直接定义xx时间后执行某项任务的话,貌似crontab比较困难,而使用swoole的swoole_timer_after可以实现:
swoole_timer_after(120000, function() use ($str) { //2分钟后执行 $this->sendReport(); //发送报表 echo "send report, $str\n"; }); 对于场景三,用来作尝试请求,请求失败后继续,如果成功则停止请求。用crontab也能解决,但是比较傻,比如设置每隔5分钟请求一次,不管成功会失败都会去执行一次。而用swoole定时器则智能多了。
swoole_timer_tick(5*60*1000, function($timer) use ($url) { // 启用定时器,每5分钟执行一次 $rs = $this->postUrl($url); if ($rs) { //业务代码... swoole_timer_clear($timer); // 停止定时器 echo date('Y-m-d H:i:s'). "请求接口任务执行成功\n"; } else { echo date('Y-m-d H:i:s'). "请求接口失败,5分钟后再次尝试\n"; } }); 示例代码
新建文件\src\App\Task.php:
namespace Helloweba\Swoole; use swoole_server; /** * 任务调度 */ class Task { protected $serv; protected $host = '127.0.0.1'; protected $port = 9506; // 进程名称 protected $taskName = 'swooleTask'; // PID路径 protected $pidPath = '/run/swooletask.pid'; // 设置运行时参数 protected $options = [ 'worker_num' => 4, //worker进程数,一般设置为CPU数的1-4倍 'daemonize' => true, //启用守护进程 'log_file' => '/data/log/swoole-task.log', //指定swoole错误日志文件 'log_level' => 0, //日志级别 范围是0-5,0-DEBUG,1-TRACE,2-INFO,3-NOTICE,4-WARNING,5-ERROR 'dispatch_mode' => 1, //数据包分发策略,1-轮询模式 'task_worker_num' => 4, //task进程的数量 'task_ipc_mode' => 3, //使用消息队列通信,并设置为争抢模式 ]; public function __construct($options = []) { date_default_timezone_set('PRC'); // 构建Server对象,监听127.0.0.1:9506端口 $this->serv = new swoole_server($this->host, $this->port); if (!empty($options)) { $this->options = array_merge($this->options, $options); } $this->serv->set($this->options); // 注册事件 $this->serv->on('Start', [$this, 'onStart']); $this->serv->on('Connect', [$this, 'onConnect']); $this->serv->on('Receive', [$this, 'onReceive']); $this->serv->on('Task', [$this, 'onTask']); $this->serv->on('Finish', [$this, 'onFinish']); $this->serv->on('Close', [$this, 'onClose']); } public function start() { // Run worker $this->serv->start(); } public function onStart($serv) { // 设置进程名 cli_set_process_title($this->taskName); //记录进程id,脚本实现自动重启 $pid = "{$serv->master_pid}\\n{$serv->manager_pid}"; file_put_contents($this->pidPath, $pid); } //监听连接进入事件 public function onConnect($serv, $fd, $from_id) { $serv->send( $fd, "Hello {$fd}!" ); } // 监听数据接收事件 public function onReceive(swoole_server $serv, $fd, $from_id, $data) { echo "Get Message From Client {$fd}:{$data}\n"; //$this->writeLog('接收客户端参数:'.$fd .'-'.$data); $res['result'] = 'success'; $serv->send($fd, json_encode($res)); // 同步返回消息给客户端 $serv->task($data); // 执行异步任务 } /** * @param $serv swoole_server swoole_server对象 * @param $task_id int 任务id * @param $from\id int 投递任务的worker_id * @param $data string 投递的数据 */ public function onTask(swoole_server $serv, $task_id, $from_id, $data) { swoole_timer_tick(30000, function($timer) use ($task_id) { // 启用定时器,每30秒执行一次 $memPercent = $this->getMemoryUsage(); echo date('Y-m-d H:i:s') . '当前内存使用率:'.$memPercent."\n"; }); } /** * @param $serv swoole_server swoole_server对象 * @param $task_id int 任务id * @param $data string 任务返回的数据 */ public function onFinish(swoole_server $serv, $task_id, $data) { // } // 监听连接关闭事件 public function onClose($serv, $fd, $from_id) { echo "Client {$fd} close connection\n"; } public function stop() { $this->serv->stop(); } private function getMemoryUsage() { // MEMORY if (false === ($str = @file("/proc/meminfo"))) return false; $str = implode("", $str); preg_match_all("/MemTotal\s{0,}\:+\s{0,}([\d\.]+).+?MemFree\s{0,}\:+\s{0,}([\d\.]+).+?Cached\s{0,}\:+\s{0,}([\d\.]+).+?SwapTotal\s{0,}\:+\s{0,}([\d\.]+).+?SwapFree\s{0,}\:+\s{0,}([\d\.]+)/s", $str, $buf); //preg_match_all("/Buffers\s{0,}\:+\s{0,}([\d\.]+)/s", $str, $buffers); $memTotal = round($buf[1][0]/1024, 2); $memFree = round($buf[2][0]/1024, 2); $memUsed = $memTotal - $memFree; $memPercent = (floatval($memTotal)!=0) ? round($memUsed/$memTotal*100,2):0; return $memPercent; } } 我们以场景一为例,在onTask启用定时任务,每隔30秒计算一次内存使用率。实际应用中可以把计算好的内存按时间写入数据库等存储中,然后可以根据前端需求用来渲染成统计图表,如:
接着服务端代码 public\taskServer.php :
false ]; $ser = new Task($opt); $ser->start();
客户端代码 public\taskClient.php :
client = new swoole_client(SWOOLE_SOCK_TCP); } public function connect() { if( !$this->client->connect("127.0.0.1", 9506 , 1) ) { echo "Error: {$this->client->errMsg}[{$this->client->errCode}]\n"; } fwrite(STDOUT, "请输入消息 Please input msg:"); $msg = trim(fgets(STDIN)); $this->client->send( $msg ); $message = $this->client->recv(); echo "Get Message From Server:{$message}\n"; } } $client = new Client(); $client->connect(); 验证效果
1.启动服务端:
php taskServer.php
2.客户端输入:
另开命令行窗口,执行
[root@localhost public]# php taskClient.php
请输入消息 Please input msg:hello
Get Message From Server:{"result":"success"} [root@localhost public]# 3.服务端返回:
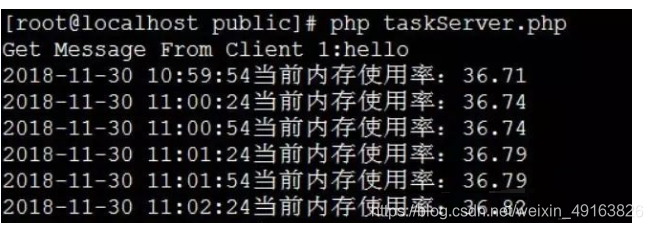
如果返回上图中的结果,则定时任务正常运行,我们会发现每隔30秒会输出一条信息。
更多学习内容可以访问
以上内容希望帮助到大家,很多PHPer在进阶的时候总会遇到一些问题和瓶颈,业务代码写多了没有方向感,不知道该从那里入手去提升,对此我整理了一些资料,包括但不限于:分布式架构、高可扩展、高性能、高并发、服务器性能调优、TP6,laravel,YII2,Redis,Swoole、Swoft、Kafka、Mysql优化、shell脚本、Docker、微服务、Nginx等多个知识点高级进阶干货需要的可以免费分享给大家,需要的可以加入我的PHP技术交流群
转载地址:http://pgdk.baihongyu.com/